数据存储
graph模块负责将agent采集到的监控数据存储到rrd中。根据源代码整理了如下流程图。
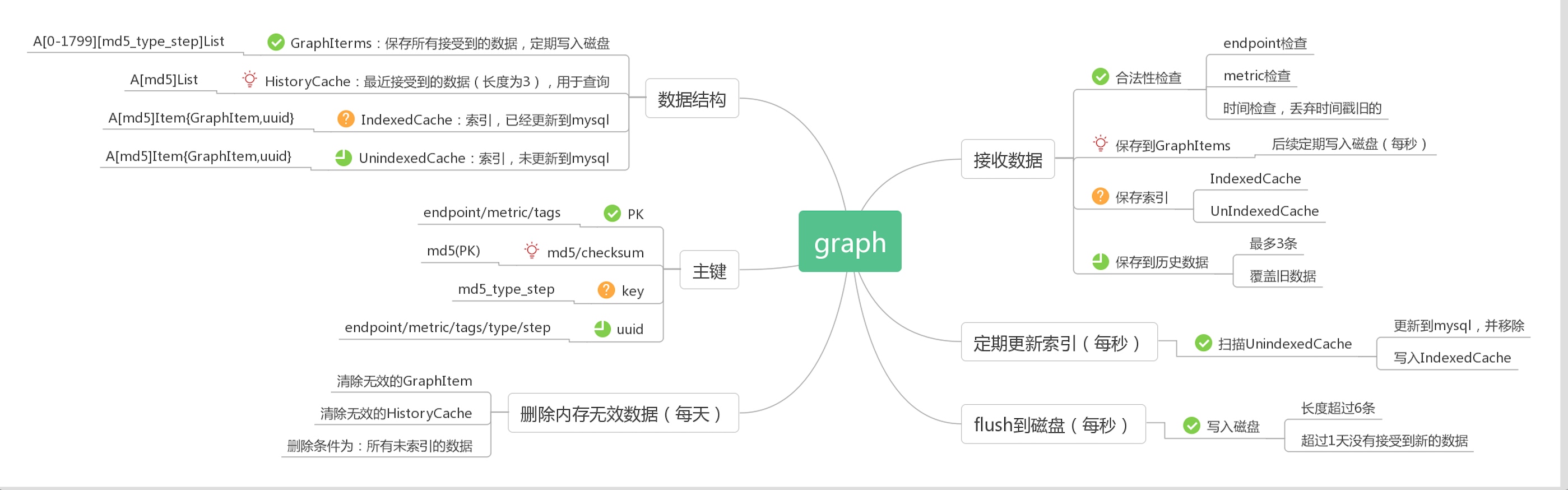
需要了解四个关键的数据结构:
- GraphItems:一个用来保存接收到的所有监控数据(之后会定期写入磁盘rrd文件中)
- HistoryCache: 保存最近三次接收到的历史数据(主要用于绘图数据的查询)
- IndexedItemCache: 已经写入mysql的索引数据
- UnIndexedItemCache: 尚未写入mysql的索引
大致流程为:
- 接收数据=>保存监控数据=>保存索引=>保存历史数据
- 定期将内存数据GraphItems写入磁盘
- 定期更新索引到mysql
1、2、3这三个过程并行运行
流程图
扩容
简介
首先说明falcon需要扩容的场景:数据量过大,整个graph集群中,单台graph占用的内存达到机器的瓶颈,若短期内不处理,机器的内存使用将超限,严重的将导致机器宕机。
因此,扩容的意思即是:增加graph集群使用的机器数量,分散监控数据,使得单台graph占用的机器内存减小。
falcon绘图数据的存储使用的是rrd,依据的算法是一致性hash算法。因此,增加机器意味着之前写入A机器的数据现在可能写入新增加的机器B,必须要把旧机器上A的数据迁移到新的机器B上,才能保证查询数据的正确性。
原理
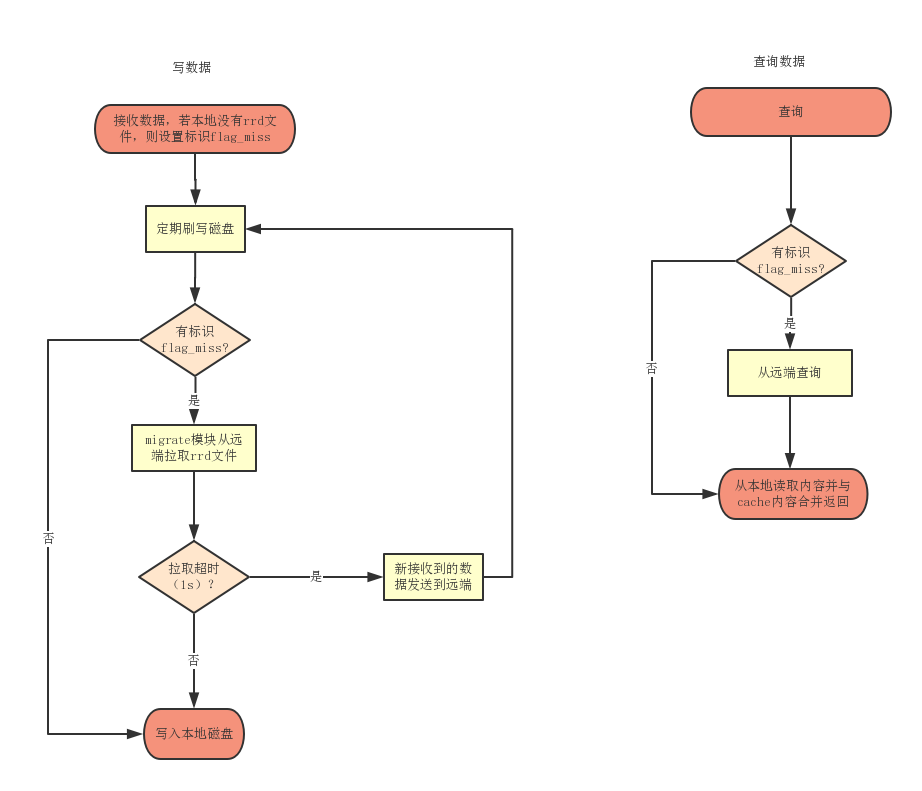
知道了为什么扩容以及扩容的基础知识,就可以更好的理解其原理了。
- 当增加机器时,部分数据会写入新机器B(这些数据在未扩容之前是写入A机器),数据写入时,先不落盘,而是先从旧的机器A上拉取历史数据(就是一个rrd文件),拉取成功,则将整个文件写入本地磁盘。若拉取超时(1s),则将新接收到的数据传送给旧的A机器。待下一个周期再重复此过程,直到A机器上的历史数据写入本地磁盘成功。
- 为保证扩容过程中依然可以查看绘图数据,当查询数据时落到新加的机器时,若本地有数据则直接返回本地数据,若本地没有数据则从旧的机器A上查询并与本地cache合并返回给用户。
流程图
扩容过程
- 配置新的graph实例
- 重启所有graph(最好一台一台重启,防止重启过程中丢失数据)
- 修改transfer配置,加入新graph,重启
- 修改api配置,加入新graph,重启
- 等待扩容完毕
此过程可参见作者写的详细文档扩容操作过程
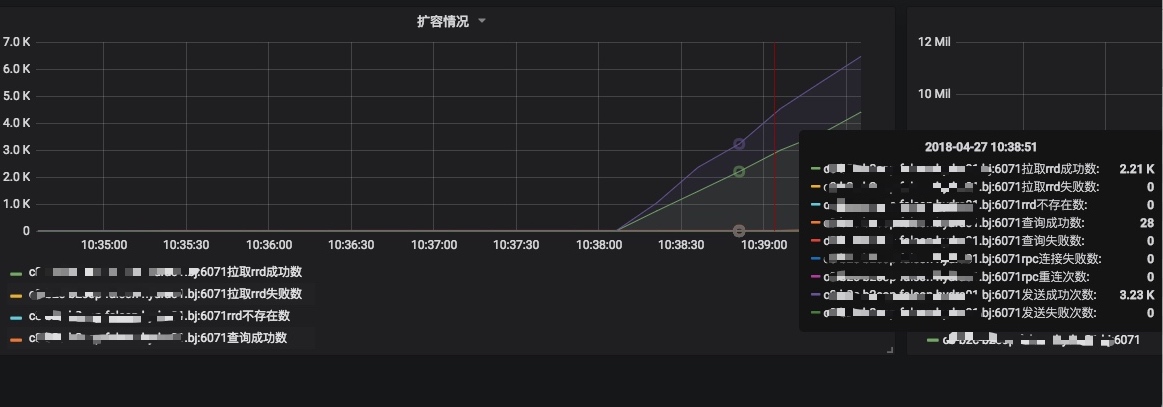
扩容过程监控
一些关键指标
- 扩容相关
curl http://localhost:6071/api/v2/counter/migrate
| 名称 | 解释 | 备注 |
|---|---|---|
| FETCH_S_ERR | 拉取rrd文件失败 | 严重错误,数据堆积内存,无法写入本地磁盘 |
| FETCH_S_SUCCESS | 拉入rrd文件成功 | 成功标识 |
| FETCH_S_ISNOTEXIST | 远端机器没有rrd文件 | 直接将数据写入本地,成功标识 |
| SEND_S_SUCCESS | 向远端机器发送数据成功 | 说明fetch超时了,将数据写入远端成功 |
| SEND_S_ERR | 向远端机器发送数据失败 | 说明fetch超时了,写入远端也失败了,将会有数据丢失 |
| QUERY_S_SUCCESS | 查询成功 | 扩容过程中有查询操作,从远端查询数据成功 |
| QUERY_S_ERR | 查询失败 | 扩容过程中有查询操作,从远端查询数据失败(不影响扩容) |
- graph相关
curl http://localhost:6071/counter/all
| 名称 | 解释 | 备注 |
|---|---|---|
| GraphRpcRecvCnt | graph接收到的数据个数 |
监控图
参考