1.open-falcon整体架构
下图是open-falcon的整体架构,模块比较多,可以看完整篇文章介绍再回头看这个架构图。
注:图中的memcache并未使用,uic模块现已更名为fe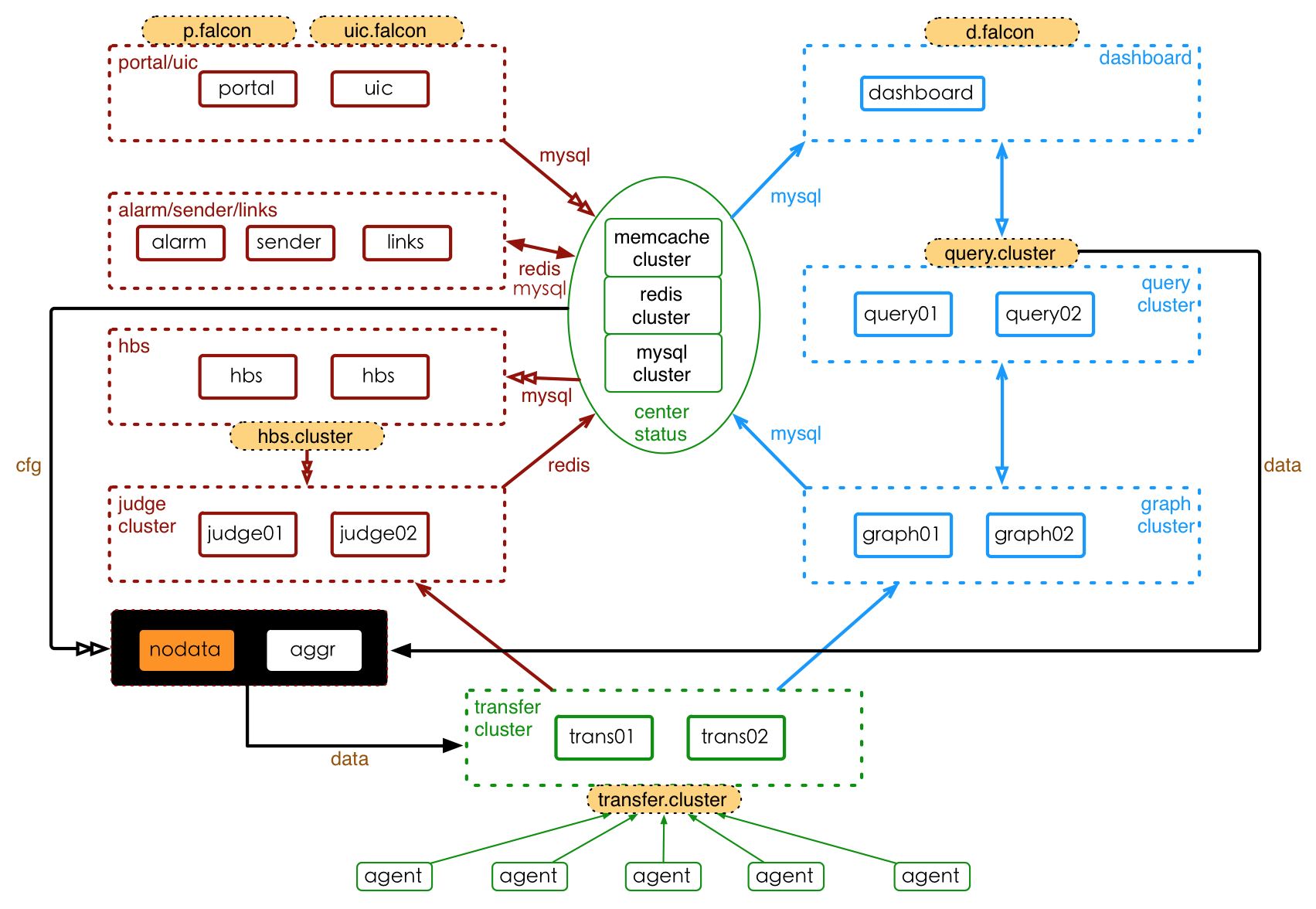
2.主要组件
open-falcon主要包括以下几大组件
核心组件:
- agent: 数据采集组件,需要部署到每台需要监控的机器上,会自动采集一些基础监控信息并上报。
- transfer: 数据接收及转发组件
- graph: 历史数据存储组件,接收transfer发送的监控数据并保存在rrd数据库中
- judge: 告警判断组件,接收transfer发送的监控数据,并根据告警策略判断事件是否需要告警。
- hbs: 心跳服务器,用于接收agent心跳数据、向agent同步其他监控项、从mysql中同步告警策略。
- query: 数据查询组件,面向终端用户,主要用于查询graph绘图数据并返回给用户
- alarm: 告警组件,judge组件判断后需要告警的事件会写入redis,alarm组件负责定期去redis中读取事件,并对告警事件进行处理转化为短信及邮件。
- sender 告警信息发送组件,alarm组件处理完成的短信及邮件会分别写入短信以及邮件redis队列中,sender组件定期从中读取短信和邮件内容,调用公司自己提供的短信和邮件发送接口, 发送告警信息。
web组件:
- dashboard:绘图展示组件,所有的监控数据都可以在此界面上查看,只要提供endpoint、metric就可以查看绘图数据。
- portal :策略配置界面,用于配置告警策略,保存在mysql数据库中。
- fe :后台管理界面统一入口,可跳转到dashboard、portal界面,并提供用户信息管理,告警接收人,告警接收分组等。
非必须组件:
- nodata :用于数据上报丢失的监控。例如,当几分钟之内接收不到某机器的agent.alive的信息,可以说明该机器agent崩溃或该机器网络异常或该机器死机。
- links :报警合并组件,alarm中会对低优先级的事件进行报警合并,需要用到此模块产生一个短url链接并将合并后的报警内容保存到mysql数据库中。
- aggregator:集群监控组件。可提供某一个集群机器的某项监控数据。比如某一个分组(多台机器)的网络流量
数据存储组件:
- rrd :基于时间序列的数据库,用于存储上报的历史监控数据
- mysql :作为web界面的数据库,保存用户信息、告警策略、机器信息、监控screen信息、索引信息等等
- redis :模块与模块之间提供数据缓存队列,保存告警事件、告警合并后事件、告警短信。
3.主要组件详细介绍
1)agent
每台需要监控的机器都要部署一个agent,进行监控数据采集,采集的数据可分为以下几类:
- agent默认会去采集一些基础监控信息,例如cpu、磁盘、内存、网络流量等等
- 用户配置的需要主动监控的信息,目前包括:端口存活(port.listen)、目录磁盘使用量(du -bs)、url监控(否是返回200)
- 用户主动上报的监控数据(agent提供一个http接口,用于接收用户主动push的监控数据,数据格式符合规范即可)
agent支持用户自定义上传的监控数据格式如下: - endpoint:某一监控项所属的机器,open-falcon使用的是机器的hostname
- metric:具体的监控项名词,例如cpu.idle表示cpu空闲时间
- timestamp:时间戳,监控数据上报的时间
- step:某一监控数据上报的时间周期,默认60s上报一次
- counterType:rrd数据库支持的数据格式,主要有GAUGE、COUNTER等,详细信息可搜索下rrdtool。
- tags:标签,用于更加细致的区分监控数据,方便告警。例如cpu.idle/group=ops,project=ceph表示ops组的ceph项目上传的cpu.idle监控数据。
2)HBS
HBS(HeartBeat server)主要负责以下几个功能:
- agent自动发现功能。部署了agent的机器会定期向HBS发送心跳数据,其中包含了该机器的ip、hostname、agent版本。
- 自定义监控配置同步。agent定期从HBS获取用户自定义的监控配置项,然后进行数据采集上报
- 从mysql中同步告警策略。HBS定期从mysql中同步告警策略,并保存在内存中,供judge组件查询。
3)transfer
transfer模块接收到agent模块上报的数据后,会将其转发给graph组件和judge组件,分别用于存储历史数据和告警判断。
为保证可用性,可以配置多个transfer实例,目前我们配置2个。agent在上报数据时,随机选择一个transfer发送,若发送失败才会尝试选择另外一个transfer发送数据。可以保证在一个transfer崩溃时,数据依然可以正常上报。
graph和judge同样可配置多个实例,目前我们是各配置2个。transfer模块在向graph和judge转发数据时,使用一致性hash算法,选择将数据发送给某一台graph/judge实例。
4)graph
由于监控数据量庞大,单独使用一个graph实例,在数据量逐渐增长后会出现磁盘空间不够的情况。因此根据监控的数据量的大小,graph通常需要配置多个实例,实现一个graph集群。
transfer在转发数据给graph时,会根据一致性hash算法选择转发到哪台graph。
graph数据存储选择的是rrd数据库,详细信息科查询rrdtool相关概念
5)judge
通graph一样,每一条上报的监控数据都需要judge进行告警判断,对于大量的监控数据来说,一台judge压力过大。因此同样可配置多个judge实例,由一致性hash算法选择将数据发送给任意一台judge进行告警判断。
juege组件定期从hbs组件同步告警策略,一条监控数据上报后,judge查询该数据对应的告警策略,然后进行告警判断,最后将满足告警条件的事件按照优先级分别写入不同的redis队列。
6)alarm
judge组件进行告警判断后会将需要告警的事件按照优先级写入redis队列,alarm组件定期去读取这个队列,然后将告警事件转换为告警短息,主要包括:从告警事件中提取告警内容,根据公司短息格式要求产生告警短信内容,读取告警接收人信息,最后组合成一条条告警短信写入redis短信队列。对于低优先级的告警事件,alarm同时进行告警合并,并将告警合并后的短信写入redis短信队列。
7)sender
sender组件定期从redis短息队列和邮件队列中读取短信和邮件,调用短信和邮件接口发送告警信息。将告警短息放入redis中可以防止短信量过大导致短信接口发送不完全,最后导致信息丢失。
8)nodata
falcon可以通过agent主动上报监控数据,根据监控数据来判断系统是否异常。但是无法应对由于某些原因(网络故障、机器死机、agent崩溃等)导致监控数据未上报的情况。
nodata的作用就是在发现监控数据未上报时,由nodata主动上报一个伪数据,用户创建相关的nodata告警策略,当接收到此伪数据告警时便可以发现某个监控指标数据未上报。
我们目前主要使用nodata进行宕机监控。
4、falcon工作基本流程
简化的falcon基本工作流程可描述如下图所示:
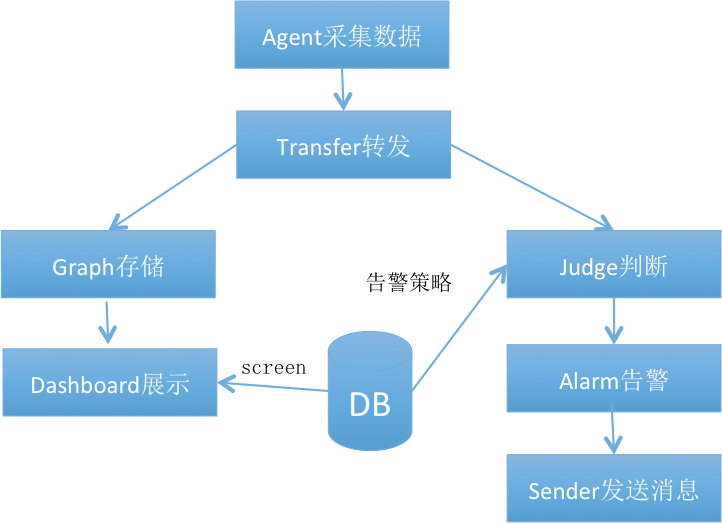
ps:更加详细的流程可以去看顶部的详细架构图